mercredi 20 novembre 2024
Par admin le mercredi 20 novembre 2024, 23:10 - PostgreSQL
Ah, les bases de données… Ces monstres sacrés de l’informatique. Vous en avez probablement entendu parler : PostgreSQL, MySQL, MongoDB. Leurs noms évoquent des lignes de commande barbares et des migraines annoncées, non ? Mais attendez ! Et si je vous disais qu’il existe une façon de jouer avec PostgreSQL, sans installation compliquée, sans serveurs capricieux, directement depuis votre navigateur ? Bienvenue dans l’univers de database.build, le petit génie qui rend les bases de données aussi accessibles qu’un site de recettes de cuisine.
Lire la suite...
aucun rétrolien
samedi 30 mars 2024
Par admin le samedi 30 mars 2024, 22:16 - PostgreSQL
Les bases de données et le machine learning... Deux mondes fascinants qui, jusqu'à récemment, semblaient évoluer sur des chemins parallèles. Mais que diriez-vous si je vous disais qu'il est désormais possible de marier ces deux univers directement au sein de votre base de données PostgreSQL ? Laissez-moi vous présenter PostgresML, la fusion parfaite entre stockage de données robuste et intelligence artificielle avancée.
Lire la suite...
aucun rétrolien
mardi 16 mai 2023
Par admin le mardi 16 mai 2023, 23:08 - Crypto-monnaies

Dans le monde des cryptomonnaies, le minage est le processus par lequel les transactions sont vérifiées et ajoutées à la blockchain publique, le grand livre des transactions passées. C'est aussi le moyen par lequel de nouvelles cryptomonnaies sont libérées. Cela nécessite une grande quantité de calculs, et c'est là que l'"effort de minage" entre en jeu.
Lire la suite...
aucun rétrolien
Par admin le mardi 16 mai 2023, 22:26 - Crypto-monnaies

Nous allons plonger dans l'univers de Dogecoin (DOGE), la cryptomonnaie qui a commencé comme une blague et qui est maintenant devenue un phénomène mondial.
Lire la suite...
aucun rétrolien
dimanche 14 mai 2023
Par admin le dimanche 14 mai 2023, 10:40 - Android
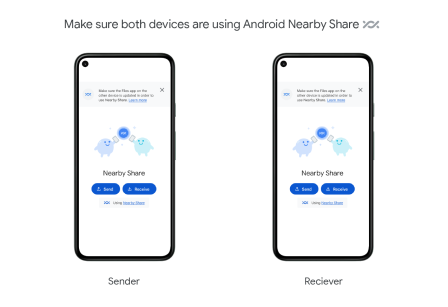
Google Nearby Share est un protocole de partage de fichiers développé par Google pour les appareils Android, similaire à la fonctionnalité AirDrop d'Apple sur iOS et macOS.
Lire la suite...
aucun rétrolien
dimanche 7 mai 2023
Par admin le dimanche 7 mai 2023, 16:50 - Crypto-monnaies

Nous allons parler de Kawpow, un algorithme de hachage qui est devenu un sujet brûlant dans l'univers des cryptomonnaies.
Qu'est-ce que Kawpow ?
Kawpow est un algorithme de preuve de travail (Proof of Work, PoW) utilisé par la cryptomonnaie Ravencoin (RVN). L'algorithme a été introduit en 2020 en tant que mise à jour du réseau Ravencoin. Il s'agit d'une adaptation de ProgPoW (Programmatic Proof of Work), conçu pour résister à l'ASIC (Application-Specific Integrated Circuit), des machines spécialisées dans le minage de cryptomonnaie.
Lire la suite...
aucun rétrolien
jeudi 13 avril 2023
Par admin le jeudi 13 avril 2023, 22:54 - Intelligence Artificielle
ChatGPT est un outil puissant, mais qui à l'heure où cet article est rédigé, est limité aux données à fin 2021. Souvent ses réponses peuvent également être peu précises sur certaines informations ou données sur une personne, une société, ou un produit par exemple. Alors si vous avez besoin, pour votre support technique, de puiser dans votre base interne de connaissances mise à jour régulièrement et bien nous allons ajouter ces données personnelles à ChatGPT, et uniquement pour votre usage interne. Rien de ce que vous ajouterez à ce système ne sera publié dans le ChatGPT grand public.
Lire la suite...
aucun rétrolien
dimanche 9 avril 2023
Par admin le dimanche 9 avril 2023, 17:54 - Général

Apache Superset est une plateforme de visualisation de données open source, qui permet de créer des tableaux de bord interactifs et de la visualisation de données à partir de différentes sources. Il permet aux utilisateurs d'explorer, d'analyser et de présenter des données de manière visuelle, sans nécessiter de connaissances en programmation ou en statistiques.
Lire la suite...
aucun rétrolien
samedi 25 mars 2023
Par admin le samedi 25 mars 2023, 01:37 - Intelligence Artificielle
Le Large Margin Learning to Rank, ou LLM pour faire court, est une technique d'apprentissage automatique qui peut sembler complexe à première vue, mais qui est en réalité très utile pour améliorer les résultats de recherche sur les sites web.
Lire la suite...
aucun rétrolien
mercredi 22 mars 2023
Par admin le mercredi 22 mars 2023, 23:26 - Intelligence Artificielle

Nous allons parler de la façon de rédiger des Prompts pour ChatGPT qui donnent l'impression que ce sont des humains qui répondent aux demandes, et non pas une IA.
Lire la suite...
aucun rétrolien
dimanche 19 mars 2023
Par admin le dimanche 19 mars 2023, 12:05 - Intelligence Artificielle

ChatGPT est dans la bouche de tout le monde en ce moment. La mise à disposition de cette Intelligence Artificielle (IA) sous forme de Chat par OpenAI a fait ouvrir les yeux au monde sur les capacités ou potentialités probables des IA dans notre quotidien. Mais savez-vous utiliser ChatGPT efficacement ?
Lire la suite...
aucun rétrolien
dimanche 9 octobre 2022
Par admin le dimanche 9 octobre 2022, 16:55 - PostgreSQL
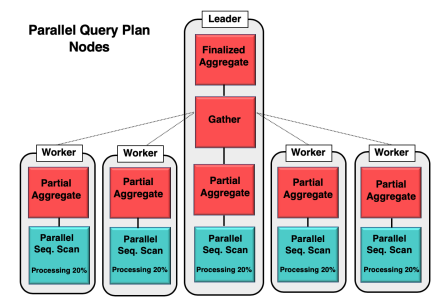
Le query parallelism est une fonctionnalité intégrée dans PostgreSQL depuis la version 9.6 qui permet de diviser une requête complexe en plusieurs tâches parallèles qui sont exécutées simultanément. Cette fonctionnalité permet d'améliorer les performances en répartissant la charge de travail sur plusieurs cœurs de processeur.
Lire la suite...
aucun rétrolien
dimanche 2 octobre 2022
Par admin le dimanche 2 octobre 2022, 20:25 - Crypto-monnaies
 Dans l'univers du minage de cryptomonnaies, le terme "pool de minage" fait référence à un groupe de mineurs qui combinent leur puissance de calcul pour augmenter leurs chances de gagner des récompenses de minage. Aujourd'hui, nous allons examiner comment configurer votre propre pool de minage en utilisant l'application p2pool pour miner du Monero (XMR).
Dans l'univers du minage de cryptomonnaies, le terme "pool de minage" fait référence à un groupe de mineurs qui combinent leur puissance de calcul pour augmenter leurs chances de gagner des récompenses de minage. Aujourd'hui, nous allons examiner comment configurer votre propre pool de minage en utilisant l'application p2pool pour miner du Monero (XMR).
Lire la suite...
aucun rétrolien
dimanche 25 septembre 2022
Par admin le dimanche 25 septembre 2022, 19:30 - PostgreSQL
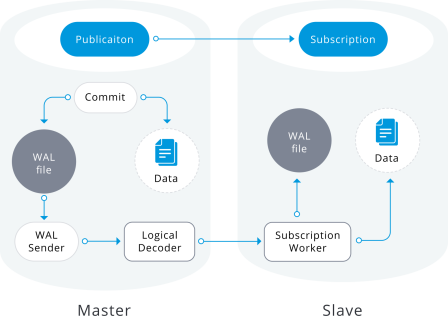
PostgreSQL intègre depuis la version 9.4 un système de réplication logique, elle l'a rendu accessible à tous véritablement depuis la version 10 avec les fonctions de publication et d'abonnement. Mais avant tout, qu'est-ce que la réplication logique ?
Lire la suite...
aucun rétrolien
dimanche 28 août 2022
Par admin le dimanche 28 août 2022, 17:30 - Crypto-monnaies

Permettez-moi de vous présenter Monero (XMR), une cryptomonnaie qui se distingue par son engagement en faveur de la confidentialité et de l'anonymat.
Lire la suite...
aucun rétrolien
dimanche 8 mai 2022
Par admin le dimanche 8 mai 2022, 22:46 - PostgreSQL

Les CTE sont un moyen pratique de définir des sous-requêtes réutilisables dans une requête principale. Les CTE sont similaires aux vues, mais contrairement aux vues, elles ne sont pas stockées en permanence dans la base de données. Au lieu de cela, elles sont définies dans la requête elle-même et ne peuvent être référencées que dans la requête qui les contient.
Lire la suite...
aucun rétrolien
dimanche 21 novembre 2021
Par admin le dimanche 21 novembre 2021, 12:01 - PostgreSQL
Toujours dans les nouvelles syntaxes apparues dans la release 14 de PostgreSQL autour de la récursivité et après avoir vu la clause CYCLE dans un précédent article, nous allons étudier la clause SEARCH.
Lire la suite...
aucun rétrolien
jeudi 11 novembre 2021
Par admin le jeudi 11 novembre 2021, 20:54 - PostgreSQL
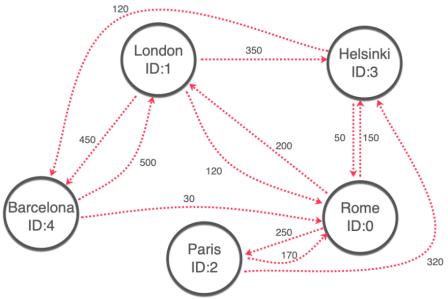
Tout d'abord, voyons ce qu'est un SELECT récursif. Il s'agit d'une requête qui se réfère à elle-même dans la clause FROM pour produire une série de résultats itératifs. Cette fonctionnalité est souvent utilisée pour parcourir des structures de données hiérarchiques telles que les arbres.
Lire la suite...
aucun rétrolien
vendredi 24 septembre 2021
Par admin le vendredi 24 septembre 2021, 21:15 - PostgreSQL
Le LATERAL JOIN est une extension puissante de la clause JOIN standard dans PostgreSQL. Contrairement à un JOIN normal, qui combine les lignes de deux tables en fonction d'une condition de jointure, un LATERAL JOIN permet de combiner les lignes d'une table avec les résultats d'une requête sur une autre table.
Lire la suite...
aucun rétrolien
dimanche 17 mai 2020
Par admin le dimanche 17 mai 2020, 14:41 - PostgreSQL

Cela ne vous est peut-être pas encore arrivé, ou vous lisez peut-être cet article pour juste chercher à comprendre ce que sont ces index INVALID car vous venez de les découvrir sur votre environnement.
Après de longues années d'utilisation de PostgreSQL je n'avais pas encore été confronté à ce phénomène. Il m'est apparu dans plusieurs cas de figure que nous allons rapidement détailler et surtout solutionner, enfin par les méthodes que j'ai pu trouver de mon côté.
Lire la suite...
aucun rétrolien
